第四章-MySQL
1、Select 语句完整的执行顺序 难度系数:⭐
SQL Select 语句完整的执行顺序:
1. from 子句组装来自不同数据源的数据;
2. where 子句基于指定的条件对记录行进行筛选;
3. group by 子句将数据划分为多个分组;
4. 使用聚集函数进行计算;
5. 使用 having 子句筛选分组;
6. 计算所有的表达式;
7. select 的字段;
8. 使用 order by 对结果集进行排序。
2、 难度系数:⭐⭐
事务的基本要素(ACID)
- 原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位
- 一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如 A 向 B 转账,不可能 A 扣了钱,B 却没收到。
- 隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如 A 正在从一张银行卡中取钱,在 A 取钱的过程结束前,B 不能向这张卡转账。
- 持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
:
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 读提交(read-committed) | 否 | 是 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
事务的并发问题
- 脏读:,然后 B 回滚操作,那么 A 读取到的数据是脏数据
- 不可重复读:事务 A 多次读取同一数据,事务 B 在事务 A 多次读取的过程中,对数据作了更新并提交,导致事务 A 多次读取同一数据时,结果 不一致
- 幻读:系统管理员 A 将数据库中所有学生的成绩从具体分数改为 ABCDE 等级,但是系统管理员 B 就在这个时候插入了一条具体分数的记录,当系统管理员 A 改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
- 脏读: 隔离级别为 读提交、可重复读、串行化可以解决脏读
- 不可重复读:隔离级别为可以解决不可重复读
- 幻读:隔离级别为可以解决幻读、
小结:
不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
3、 难度系数:⭐
| MyISAM | InnoDB | |
|---|---|---|
| 事务 | 不支持 | 支持 |
| 锁 | 表锁 | 表锁、行锁 |
| 文件存储 | 3 个 | 1 个 |
| 外键 | 不支持 | 支持 |
4、悲观锁和乐观锁的怎么实现 难度系数:⭐⭐
悲观锁:select...for update 是 MySQL 提供的实现悲观锁的方式。
例如:select price from item where id=100 for update
此时在 items 表中,id 为 100 的那条数据就被我们锁定了,其它的要执行 select price from items where id=100 for update的事务必须等本次事务提交之后才能执行。这样我们可以保证当前的数据不会被其它事务修改。MySQL 有个问题是 select...for update 语句执行中所有扫描过的行都会被锁上,因此在 MySQL 中用悲观锁务必须确定走了索引,而不是全表扫描,否则将会将整个数据表锁住。
乐观锁:乐观锁相对悲观锁而言,它认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回错误信息,让用户决定如何去做。
利用数据版本号(version)机制是乐观锁最常用的一种实现方式。一般通过为数据库表增加一个数字类型的 “version” 字段,当读取数据时,将 version 字段的值一同读出,数据每更新一次,对此 version 值+1。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的 version 值进行比对,如果数据库表当前版本号与第一次取出来的 version 值相等,则予以更新,否则认为是过期数据,返回更新失败。
举例:
-- 1: 查询出商品信息
select (quantity,version) from items where id=100;
-- 2: 根据商品信息生成订单
insert into orders(id,item_id) values(null,100);
-- 3: 修改商品的库存
update items set quantity=quantity-1,version=version+1 where id=100 and version=#{version};5、聚簇索引与非聚簇索引区别 难度系数:⭐⭐
都是 B+树的数据结构
- 聚簇索引:将数据存储与索引放到了一块、并且是按照一定的顺序组织的,找到索引也就找到了数据,数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的
- 非聚簇索引叶子节点不存储数据、存储的是数据行地址,也就是说根据索引查找到数据行的位置再取磁盘查找数据,这个就有点类似一本书的目录,比如我们要找第三章第一节,那我们先在这个目录里面找,找到对应的页码后再去对应的页码看文章。
优势:
- 查询通过聚簇索引可以直接获取数据,相比非聚簇索引需要第二次查询(非覆盖索引的情况下)效率要高
- 聚簇索引对于范围查询的效率很高,因为其数据是按照大小排列的
- 聚簇索引适合用在排序的场合,非聚簇索引不适合
劣势;
- 维护索引很昂贵,特别是插入新行或者主键被更新导至要分页(pagesplit)的时候。建议在大量插入新行后,选在负载较低的时间段,通过 OPTIMIZETABLE 优化表,因为必须被移动的行数据可能造成碎片。使用独享表空间可以弱化碎片
- 表因为使用 uuId(随机 ID)作为主键,使数据存储稀疏,这就会出现聚簇索引有可能有比全表扫面更慢,所以建议使用 int 的 auto_increment 作为主键
- 如果主键比较大的话,那辅助索引将会变的更大,因为辅助索引的叶子存储的是主键值,过长的主键值,会导致非叶子节点占用占用更多的物理空间
6、 难度系数:⭐
失效条件:
- where 后面使用函数,
- 使用 or 条件
- 模糊查询 %放在前边
- 类型转换
- 组合索引 (最佳左前缀匹配原则)
- abc
- Bc acb bac ab ca
-- 查询条件用到了计算或者函数
explain SELECT * from test_slow_query where age = 20
explain SELECT * from test_slow_query where age +10 = 30
-- 模糊查询
EXPLAIN SELECT * from test_slow_query where NAME like '%吕布'
EXPLAIN SELECT * from test_slow_query where NAME like '%吕布%'
EXPLAIN SELECT * from test_slow_query where NAME like '吕布&'
-- 用到了or条件
EXPLAIN SELECT * from test_slow_query where NAME = '吕布' or name = "aaa"
-- 类型不匹配查询
explain SELECT * from test_slow_query where NAME = 11
explain SELECT * from test_slow_query where NAME = '11'7、B+tree 与 B-tree 区别 难度系数:⭐⭐
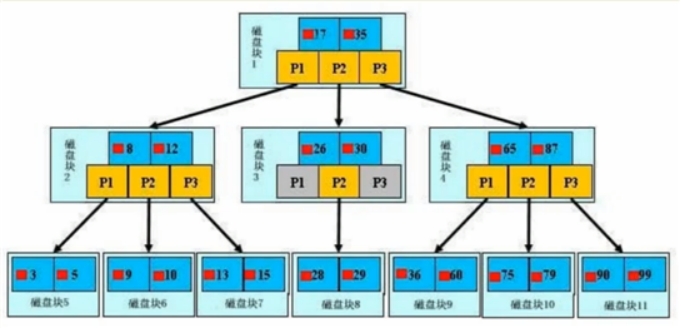
原理:分批次的将磁盘块加载进内存中进行检索,若查到数据,则直接返回,若查不到,则释放内存,并重新加载同等数据量的索引进内存,重新遍历
结构: 数据 向下的指针 指向数据的指针
特点:
- 节点排序
- 一个节点了可以存多个元索,多个元索也排序了
结构: 数据 向下的指针
特点:
- 拥有 B 树的特点
- 叶子节点之间有指针
- 非叶子节点上的元素在叶子节点上都冗余了,也就是叶子节点中存储了所有的元素,并且排好顺序
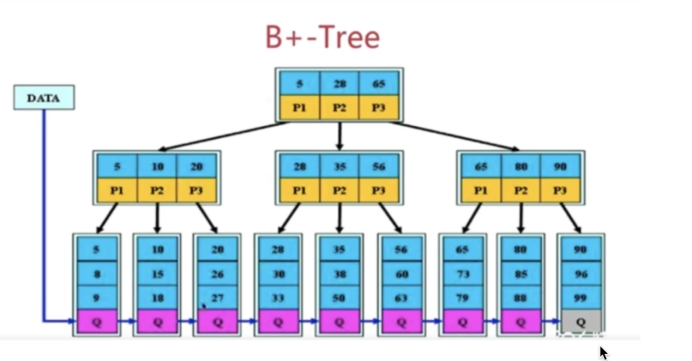
从结构上看,B+Tree 相较于 B-Tree 而言 缺少了指向数据的指针 也就红色小方块;
Mysq|索引使用的是 B+树,因为索引是用来加快查询的,而 B+树通过对数据进行排序所以是可以提高查询速度的,然后通过一个节点中可以存储多个元素,从而可以使得 B+树的高度不会太高,在 Mysql 中一个 Innodb 页就是一个 B+树节点,一个 Innodb 页默认 16kb,所以一般情况下万行左右的数据,然后通过利用 B+树叶子节点存储了所有数据并且进行了排序,并且叶子节点之间有指针,可以很好的支持全表扫描,范围查找等 SQL 语句
文章推荐:https://www.jianshu.com/p/b544d2e10726

8、以 MySQL 为例 Linux 下如何排查问题 难度系数:⭐⭐
类似提问方式:如果线上环境出现问题比如网站卡顿重则瘫痪 如何是好?
--->linux--->mysql/redis/nacos/sentinel/sluth--->可以从以上提到的技术点中选择一个自己熟悉单技术点进行分析
以 mysql 为例
1,架构层面 是否使用主从
2,表结构层面 是否满足常规的表设计规范(大量冗余字段会导致查询会变得很复杂)
3,sql 语句层面(⭐)
前提:由于慢查询日志记录默认是关闭的,所以开启数据库 mysql 的慢查询记录 的功能 从慢查询日志中去获取哪些 sql 语句时慢查询 默认 10S ,从中获取到 sql 语句进行分析
3.1 explain 分析一条 sql
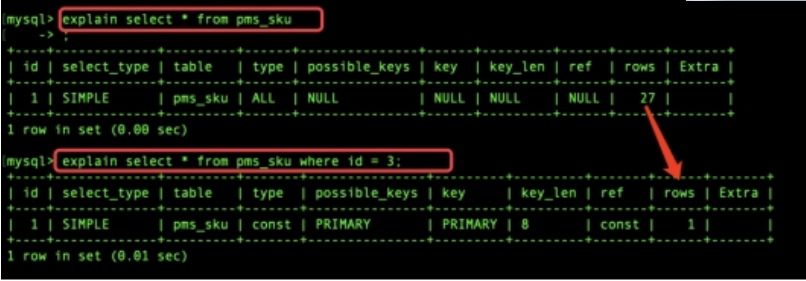
Abc def
Abc id
Ab ac id
A de
Select * from user where a=1 and b= 1 and c=1
Id:执行顺序 如果单表的话,无参考价值 如果是关联查询,会据此判断主表 从表
Select_type:simple
Table:表
Type: ALL 未创建索引 、const、 常量 ref 其他索引 、eq_ref 主键索引、
Possible_keys
Key 实际是到到索引到字段
Key_len 索引字段数据结构所使用长度 与是否有默认值 null 以及对应字段到数据类型有关,有一个理论值 有一个实际使用值也即 key_len 的值
Rows 检索的行数 与查询返回的行数无关
Extra 常见的值:usingfilesort 使用磁盘排序算法进行排序,事关排序 分组 的字段是否使用索引的核心参考值
还可能这样去提问:sql 语句中哪些位置适合建索引/索引建立在哪个位置
Select id,name,age from user where id=1 and name=”xxx” order by age
总结: 查询字段 查询条件(最常用) 排序/分组字段
补充:如何判断是数据库的问题?可以借助于 top 命令
9、如何处理慢查询 难度系数:⭐⭐
开发可以考虑创建索引
写完接口的时候可以可以进行测试,如果响应时间过长,我可以进行排查,发现没有创建索引,主动建立索引。
先实现功能,所有功能实现提交测试,批量进行性能优化,提交测试的时候可以把慢查询日志打开,设置超过一秒的 sql 就是慢 sql,都放放到慢查询日志中,拿到所有慢 sql 进行统一优化,慢查询日志默认是关闭,开启后模式超过 10 秒才算慢 sql
在业务系统中,除了使用主键进行的查询,其他的都会在测试库上测试其耗时,慢查询的统计主要由运维在做,会定期将业务中的慢查询反馈给我们。
慢查询的优化首先要搞明白慢的原因是什么?是查询条件没有命中索引?是加载了不需要的数据列?还是数据量太大?
所以优化也是针对这三个方向来的
首先分析语句,看看是否加载了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,对语句进行分析以及重写。
分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽可能的命中索引。
如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表。
具体处理流程 (阿里云 RDS 为例)
1.开启慢查询设置
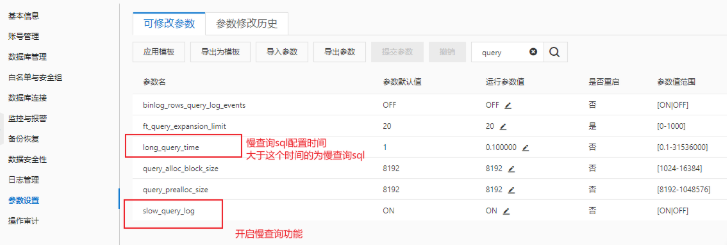
- 日志管理导出慢查询文件

- 测试环境通过 explain 执行 sql,主要关心以下字段

type:连接类型
key: MYSQL 使用的索引
rows:显示 MYSQL 执行查询的行数,简单且重要,数值越大越不好,说明没有用好索引
extra:该列包含 MySQL 解决查询的详细信息。
10、数据库分表操作 难度系数:⭐
水平分表
步长法:1000 万一张表拆分
取模法:举例:根据用户 id 取模落入不能的表
垂直分表:大表拆小表。商品信息 spu_info spu_image ...
可以说使用 Mycat 或者 ShardingSphere 等中间件来做,具体怎么做就要结合具体的场景进行分析了。可以参考:https://database.51cto.com/art/201809/583857.htm
11、MySQL 优化 难度系数:⭐
(1)尽量选择较小的列
自己举例子 5 个
(2)将 where 中用的比较频繁的字段建立索引
(3)select 子句中避免使用‘*’
(4)避免在索引列上使用计算、not in 和< >等操作
(5)当只需要一行数据的时候使用 limit 1
(6)保证单表数据不超过 500W,表磁盘不要超过 2Gb,适时分割表。针对查询较慢的语句,可以使用 explain 来分析该语句具体的执行情况。
(7)避免改变索引列的类型。
(8)选择最有效的表名顺序,from 字句中写在最后的表是基础表,将被最先处理,在 from 子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。
(9)尽量缩小子查询的结果
12、SQL 语句优化案例 难度系数:⭐
例 1:where 子句中可以对字段进行 null 值判断吗?
可以,比如 select id from t where num is null 这样的 sql 也是可以的。但是最好不要给数据库留 NULL,尽可能的使用 NOT NULL 填充数据库。不要以为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了, 不管是否插入值(NULL 也包含在内),都是占用 100 个字符的空间的,如果是 varchar 这样的变长字段,null 不占用空间。可以在 num 上设置默认值 0,确保表中 num 列没有 null 值,然后这样查询:select id from t where num= 0。
例 2:如何优化?下面的语句?
select * from admin left join log on admin.admin_id = log.admin_id where log.admin_id>10
-- 优化为
select _from (select_ from admin where admin_id>10) T1 lef join log on T1.admin_id = log.admin_id。使用 JOIN 时候,应该用小的结果驱动大的结果(left join 左边表结果尽量小如果有条件应该放到左边先处理, right join 同理反向),同时尽量把牵涉到多表联合的查询拆分多个 query(多个连表查询效率低,容易到之后锁表和阻塞)。
例 3:limit 的基数比较大时使用 between
--例如:
select * from admin order by admin_id limit 100000,10
--优化为:
select * from admin where admin_id between 100000 and 100010 order by admin_id。例 4:尽量避免在列上做运算,这样导致索引失效
--例如:
select * from admin where year(admin_time)>2014
-- 优化为:
select * from admin where admin_time> '2014-01-01′13、你们公司有哪些数据库设计规范 难度系数:⭐
(一)基础规范
1、表存储引擎必须使用 InnoD,表字符集默认使用 utf8,必要时候使用 utf8mb4
解读:
(1)通用,无乱码风险,汉字 3 字节,英文 1 字节
(2)utf8mb4 是 utf8 的超集,有存储 4 字节例如表情符号时,使用它
2、禁止使用存储过程,视图,触发器,Event
解读:
(1)对数据库性能影响较大,互联网业务,能让站点层和服务层干的事情,不要交到数据库层
(2)调试,排错,迁移都比较困难,扩展性较差
3、禁止在数据库中存储大文件,例如照片,可以将大文件存储在对象存储系统,数据库中存储路径
4、禁止在线上环境做数据库压力测试
5、测试,开发,线上数据库环境必须隔离
(二)命名规范
1、库名,表名,列名必须用小写,采用下划线分隔
解读:abc,Abc,ABC 都是给自己埋坑
2、库名,表名,列名必须见名知义,长度不要超过 32 字符
解读:tmp,wushan 谁知道这些库是干嘛的
3、库备份必须以 bak 为前缀,以日期为后缀
4、从库必须以-s 为后缀
5、备库必须以-ss 为后缀
(三)表设计规范
1、单实例表个数必须控制在 2000 个以内
2、单表分表个数必须控制在 1024 个以内
3、表必须有主键,推荐使用 UNSIGNED 整数为主键
潜在坑:删除无主键的表,如果是 row 模式的主从架构,从库会挂住
4、禁止使用外键,如果要保证完整性,应由应用程式实现
解读:外键使得表之间相互耦合,影响 update/delete 等 SQL 性能,有可能造成死锁,高并发情况下容易成为数据库瓶颈
5、建议将大字段,访问频度低的字段拆分到单独的表中存储,分离冷热数据
(四)列设计规范
1、根据业务区分使用 tinyint/int/bigint,分别会占用 1/4/8 字节
2、根据业务区分使用 char/varchar
解读:
(1)字段长度固定,或者长度近似的业务场景,适合使用 char,能够减少碎片,查询性能高
(2)字段长度相差较大,或者更新较少的业务场景,适合使用 varchar,能够减少空间
3、根据业务区分使用 datetime/timestamp
解读:前者占用 5 个字节,后者占用 4 个字节,存储年使用 YEAR,存储日期使用 DATE,存储时间使用 datetime
4、必须把字段定义为 NOT NULL 并设默认值
解读:
(1)NULL 的列使用索引,索引统计,值都更加复杂,MySQL 更难优化
(2)NULL 需要更多的存储空间
(3)NULL 只能采用 IS NULL 或者 IS NOT NULL,而在=/!=/in/not in 时有大坑
5、使用 INT UNSIGNED 存储 IPv4,不要用 char(15)
6、使用 varchar(20)存储手机号,不要使用整数
解读:
(1)牵扯到国家代号,可能出现+/-/()等字符,例如+86
(2)手机号不会用来做数学运算
(3)varchar 可以模糊查询,例如 like ‘138%’
7、使用 TINYINT 来代替 ENUM
解读:ENUM 增加新值要进行 DDL 操作
(五)索引规范
1、唯一索引使用 uniq_[字段名]来命名
2、非唯一索引使用 idx_[字段名]来命名
3、单张表索引数量建议控制在 5 个以内
解读:
(1)互联网高并发业务,太多索引会影响写性能
(2)生成执行计划时,如果索引太多,会降低性能,并可能导致 MySQL 选择不到最优索引
(3)异常复杂的查询需求,可以选择 ES 等更为适合的方式存储
4、组合索引字段数不建议超过 5 个
解读:如果 5 个字段还不能极大缩小 row 范围,八成是设计有问题
5、不建议在频繁更新的字段上建立索引
6、非必要不要进行 JOIN 查询,如果要进行 JOIN 查询,被 JOIN 的字段必须类型相同,并建立索引
解读:踩过因为 JOIN 字段类型不一致,而导致全表扫描的坑么?
7、理解组合索引最左前缀原则,避免重复建设索引,如果建立了(a,b,c),相当于建立了(a), (a,b), (a,b,c)
(六)SQL 规范
1、禁止使用 select *,只获取必要字段
解读:
(1)select *会增加 cpu/io/内存/带宽的消耗
(2)指定字段能有效利用索引覆盖
(3)指定字段查询,在表结构变更时,能保证对应用程序无影响
2、insert 必须指定字段,禁止使用 insert into T values()
解读:指定字段插入,在表结构变更时,能保证对应用程序无影响
3、隐式类型转换会使索引失效,导致全表扫描
4、禁止在 where 条件列使用函数或者表达式
解读:导致不能命中索引,全表扫描
5、禁止负向查询以及%开头的模糊查询
解读:导致不能命中索引,全表扫描
6、禁止大表 JOIN 和子查询
7、同一个字段上的 OR 必须改写问 IN,IN 的值必须少于 50 个
8、应用程序必须捕获 SQL 异常
解读:方便定位线上问题
说明:本规范适用于并发量大,数据量大的典型互联网业务,可直接参考。
14、有没有设计过数据表?你是如何设计的 难度系数:⭐
| 第一范式 | 每一列属性(字段)不可分割的,字段必须保证原子性 两列的属性值相近或者一样的,尽量合并到一列或者分表,确保数据不冗余 |
|---|---|
| 第二范式 | 每一行的数据只能与其中一行有关 即 主键 一行数据只能做一件事情或者表达一个意思, 只要数据出现重复,就要进行表的拆分 |
| 第三范式 | 数据不能存在传递关系,每个属性都跟主键有直接关联而不是间接关联 |

15、常见面试 SQL 难度系数:⭐
例 1:
| name | kecheng | fenshu |
|---|---|---|
| 张三 | 语文 | 81 |
| 张三 | 数学 | 75 |
| 李四 | 语文 | 76 |
| 李四 | 数学 | 90 |
| 王五 | 语文 | 81 |
| 王五 | 数学 | 100 |
| 王五 | 英语 | 90 |
用一条 SQL 语句查询出每门课都大于 80 分的学生姓名
select distinct name from table where name not in (select distinct name from table where fenshu< =80) 答 2:
select name from table group by name having min(fenshu)>80例 2:
学生表 如下:
| 自动编号 | 学号 | 姓名 | 课程编号 | 课程名称 | 分数 |
|---|---|---|---|---|---|
| 1 | 2005001 | 张三 | 0001 | 数学 | 69 |
| 2 | 2005002 | 李四 | 0001 | 数学 | 89 |
| 3 | 2005001 | 张三 | 0001 | 数学 | 69 |
删除除了自动编号不同,其他都相同的学生冗余信息
delete tablename where 自动编号 not in(select min(自动编号) from tablename group by 学号, 姓名, 课程编号, 课程名称, 分数)例 3:
一个叫 team 的表,里面只有一个字段 name,一共有 4 条纪录,分别是 a,b,c,d,对应四个球队,现在四个球队进行比赛,用一条 sql 语句显示所有可能的比赛组合.
- select a.name, b.name
- from team a, team b
- where a.name < b.name
例 4:
怎么把这样一个表
| year | month | amount |
|---|---|---|
| 1991 | 1 | 1.1 |
| 1991 | 2 | 1.2 |
| 1991 | 3 | 1.3 |
| 1991 | 4 | 1.4 |
| 1992 | 1 | 2.1 |
| 1992 | 2 | 2.2 |
| 1992 | 3 | 2.3 |
| 1992 | 4 | 2.4 |
查成这样一个结果
| year | m1 | m2 | m3 | m4 |
|---|---|---|---|---|
| 1991 | 1.1 | 1.2 | 1.3 | 1.4 |
| 1992 | 2.1 | 2.2 | 2.3 | 2.4 |
select year,
(select amount from aaa m where month=1 and m.year=aaa.year) as m1,
(select amount from aaa m where month=2 and m.year=aaa.year) as m2,
(select amount from aaa m where month=3 and m.year=aaa.year) as m3,
(select amount from aaa m where month=4 and m.year=aaa.year) as m4
from aaa group by year例 5:
说明:复制表(只复制结构,源表名:a 新表名:b)
select * into b from a where 1<>1 -- (where 1=1,拷贝表结构和数据内容)
-- ORACLE:
create table b As Select * from a where 1=2<>(不等于)(SQL Server Compact) 比较两个表达式。 当使用此运算符比较非空表达式时,如果左操作数不等于右操作数,则结果为 TRUE。 否则,结果为 FALSE。
例 6:
原表:
| coursed | coursename | score |
|---|---|---|
| 1 | java | 70 |
| 2 | oracle | 90 |
| 3 | xml | 40 |
| 4 | jsp | 30 |
| 5 | servlet | 80 |
为了便于阅读,查询此表后的结果显式如下(及格分数为 60):
| coursed | coursename | score | mark |
|---|---|---|---|
| 1 | java | 70 | pass |
| 2 | oracle | 90 | pass |
| 3 | xml | 40 | fail |
| 4 | jsp | 30 | fail |
| 5 | servlet | 80 | pass |
select courseid, coursename ,score ,if(score>=60, "pass","fail") as mark from course例 7:**
表名:购物信息
| 购物人 | 商品名称 | 数量 |
|---|---|---|
| A | 甲 | 2 |
| B | 乙 | 4 |
| C | 丙 | 1 |
| A | 丁 | 2 |
| B | 丙 | 5 |
给出所有购入商品为两种或两种以上的购物人记录
select * from 购物信息 where 购物人 in (select 购物人 from 购物信息 group by 购物人 having count(*) >= 2);例 8:
info 表
| date | result |
|---|---|
| 2005-05-09 | win |
| 2005-05-09 | lose |
| 2005-05-09 | lose |
| 2005-05-09 | lose |
| 2005-05-10 | win |
| 2005-05-10 | lose |
| 2005-05-10 | lose |
如果要生成下列结果, 该如何写 sql 语句?
| date | win | lose |
|---|---|---|
| 2005-05-09 | 2 | 2 |
| 2005-05-10 | 1 | 2 |
-- 答1:
SELECT
date,
sum( CASE WHEN result = "win" THEN 1 ELSE 0 END ) AS "win",
sum( CASE WHEN result = "lose" THEN 1 ELSE 0 END ) AS "lose"
FROM
info
GROUP BY
date;-- 答2:
SELECT
a.date,
a.result AS win,
b.result AS lose
FROM
( SELECT date, count( result ) AS result FROM info WHERE result = "win" GROUP BY date ) AS a
JOIN ( SELECT date, count( result ) AS result FROM info WHERE result = "lose" GROUP BY date ) AS b ON a.date = b.date;16、MySQL 中的 MVCC 是什么
多版本并发控制:读取数据时通过一种类似快照的方式将数据保存下来,这样读锁就和写锁不冲突了,不同的事务会看到自己特定版本的数据,版本链.
MVCC 只在 READ COMMITTED 和 REPEATABLE READ 两个隔离级别下工作。其他两个隔离级别和 MVCC 不兼容, 因为 READ UNCOMMITTED 总是读取最新的数据行, 而不是符合当前事务版本的数据行。而 SERIALIZABLE 则会对所有读取的行都加锁。
聚簇索引记录中有两个必要的隐藏列:
trx_id:用来存储每次对某条聚簇索引记录进行修改的时候的事务 id。
roll_pointer:每次对哪条聚簇索引记录有修改的时候,都会把老版本写入 undo 日志中。这个 roll_pointer 就是存了一个指针,它指向这条聚簇索引记录的上一个版本的位置,通过它来获得上一个版本的记录信息。(注意插入操作的 undo 日志没有这个属性,因为它没有老版本)
读已提交和可重复读的区别就在于它们生成 ReadView 的策略不同。
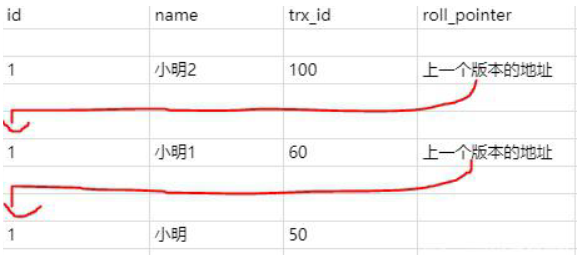
开始事务时创建 ReadView,ReadView 维护当前活动的事务 id,即未提交的事务 id,排序生成一个数组.
访问数据,获取数据中的事务 id,对比 ReadView:
如果在 ReadView 的左边(比 ReadView 都小),可以访问(在左边意味着该事务已经提交)
如果在 ReadView 的右边(比 ReadView 都大)或者就在 ReadView 中,不可以访问,获取 roll_pointer,取上一版本重新对比(在右边意味着,该事务在 ReadView 生成之后出现,在 ReadView 中意味着该事务还未提交)
已提交读隔离级别下的事务在每次查询的开始都会生成一个独立的 ReadView,而可重复读隔离级别则在第一次读的时候生成一个 ReadView,之后的读都复用之前的 ReadView。
这就是 Mysql 的 MVCC,通过版本链,实现多版本,可并发读-写,写-读。通过 ReadView 生成策略的不同实现不同的隔离级别